분석통계 방법의 간단한 설명
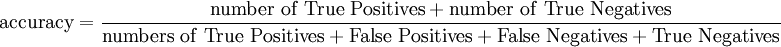
|
|
|
|
앞에서 통계를 위해서 기본적으로 알아야 할 내용들과 또 가장 핵심적인 내용을 말씀드렸습니다. 여기서는 각각의 분석통계 방법의 내용 중 중요한 몇 가지에 대해서 간단히 설명드리고자 합니다.
설명의 편의상 독립 변수와 종속 변수의 관계로 구별을 해서 말씀드리겠습니다. 아래 설명에서 -의 앞은 독립변수, 뒤는 종속변수 입니다.
|
|
|
|
|
|
1. 이산 – 이산 변수
|
|
|
|
|
|
a) 단일표본 : 2개 이상 변수의 각 범주의 관찰 빈도와 기대 빈도 사이의 통계적 차이
b) 두 독립표본 : 두 집단간의 분포 차이의 유의도 검증
c) 조건
자유도 = 1 : 전체 사례수 > 30, 각 셀의 빈도수 5 이상
자유도 > 1 : 전체 사례수 > 30, 5 미만의 기대빈도의 셀 < 모든 칸의 20%
모든 셀에 1.00 이상의 기대빈도 시 사용가능
d) 대응하는 비모수 검정
– Fisher’s exact test (자유도가 1인 경우 위의 조건을 만족치 못할 때 적용)
|
|
|
|
|
|
2. 이산-연속 변수
|
|
|
|
|
|
a) 두 집단의 평균 차이가 통계적으로 유의한지 파악(모집단의 분산을 모를 때 사용)
b) 독립 변수는 두개의 집단
c) 종속 변수는 반드시 연속 변수(등간.비율 척도)이며 정규분포를 따라야하고 관측치간에는
독립성이 있어야 함 d) 대응하는 비모수 검정
– Mann-Whitney U test
a) 동일한 표본에서 두 변수의 평균의 차이를 비교
b) 대응하는 비모수 검정
– Wilcoxon matched-pairs signed-ranks test
a) 독립 변수가 둘 이상 집단인 경우 종속 변수의 평균 차이가 유의한지 비교 (확대된 t-test)
b)종속 변수 : 반드시 등간.비율 척도
c) 대응하는 비모수 검정
– Kruskal-Wallis test
– 독립 변수가 두 개 이상인 다변량 분석
|
|
|
|
|
|
3. 연속 – 연속 변수
|
|
|
|
|
|
회귀분석(regression)과 상관분석(correlation)을 사용합니다. 회귀 분석은 변수들 간의 관계를 파악하는데 유용하며 상관분석은 두 변수간의 관련성을 선형적인 강도를 통해 알아보는 방법입니다.
a) 두 변수가 등간 또는 비율 척도 (연속 변수)
b) 조건
– 두 변수간 직선적 관계
– 각 행과 열의 분산도가 비슷
– 적어도 한 변수가 정상 분포
c) 적은 사례일 경우 신뢰할 수 없음
d) 대응하는 비모수 검정
– Spearman’s rho : 독립, 종속 변수가 서열 변수인 경우 단순 상관관계 산출
자료의 등간성 의심, 변수의 점수가 극단적 분포, 서열 척도시 적용
– Kendall’s tau b : 독립, 종속 변수가 서열 변수시 적용
a) 곡선적 관계에 있는 두 변수간의 단순 상관계수 산출 방법
b) 두 변수가 직선 관계인지 곡선 관계는 plot 등의 그래프로 확인
a) 한 변수와 다른 변수들과 관계 분석 – 변수의 값을 가지고 다른 변수의 값을 예언
즉 변수들 간의 관계를 파악하는데 유용
b) 가정
ㄱ) 주어진 자료에서 독립변수와 종속변수의 값의 분포가 직선적인 관계
ㄴ) 오차들이 독립적
ㄷ) 오차들의 분산이 일정
ㄹ) 오차들의 분포가 정상분포
c) 단순회귀분석
– 독립, 종속변수가 하나씩일 때 독립변수가 종속변수에 미치는 영향, 관계, 인과 분석
d) 다중회귀분석 – 2개 이상의 독립변수를 사용하여 독립변수와 종속변수의 관계를 알아보고자 할 때 사용
e) 더미분석
– 회귀모형에서 명목이나 서열 변수를 독립변수로 할 때
|
|
|
4. 연속 – 이산 변수
|
|
|
|
|
|
1) 로지스틱 회귀분석
a) 종속변수가 이분형이고 여러 가지 독립변수와의 관계를 파악
|
|
정확도(Accuracy)란?
“Accuracy” is also used as a statistical measure of how well a binary classification test correctly identifies or excludes a condition.
| Condition (e.g. Disease) As determined by “Gold” standard |
||||
| True | False | |||
| Test outcome |
Positive | True Positive | False Positive | → Positive Predictive Value |
| Negative | False Negative | True Negative | → Negative Predictive Value | |
| ↓ Sensitivity |
↓ Specificity |
Accuracy | ||
That is, the accuracy is the proportion of true positives and true negatives in the population. It is a parameter of the test.
An accuracy of 100% means that the test recognizes all sick and well people as such.


